robots协议是什么意思
robots协议也被称为robots.txt(统一小写字母),其被通知给因特网搜索引擎中的数据漫游(又称网络模型),并且该站点的内容不是搜索引擎中的数据漫游应当获取的,而是可以获取的数据漫游。由于一些系统软件中的URL是英文大小写比较敏感的,因此robots.txt的文件夹名称应统一为小写字母。robots.txt应置放于网站的根目录下。如果搜索引擎的数据漫游想要独立定义访问子目录时的个人行为,则自己设定的设定可以汇集到根目录下的robots.txt,或者应用robots元数据(Metadata、别名元数据)。

robots协议是什么意思
robots.txt是存有于网站根目录的一个文本文档,在文本文档里能够设定百度收录标准,搜索引擎会依据robots的标准开展爬取,robots设定为不允许爬取的,搜索引擎则不容易爬取,时尚博主的段文杰SEOblog就沒有设定robots文件,沒有设定robots协议书的状况下,意味着网站內容容许全部搜索引擎爬取,容许全部搜索引擎爬取网站的一切一个目录,那样做的缺陷是存有一些安全风险。
一般状况下90%之上的网站都设定了robots协议书,运用robots协议书屏蔽网站的一些隐私保护相对路径,保证网站更为安全性,根据robots协议书,可以设定搜索引擎只百度收录静态数据URL,而不允许百度收录动态性URL,确保网站URL的统一性,robots协议书可以屏蔽掉一切一个搜索引擎,假如不愿让某一搜索引擎百度收录你的网站,能够运用robots协议书屏蔽某一搜索引擎,robots文件虽小,功效却挺大。
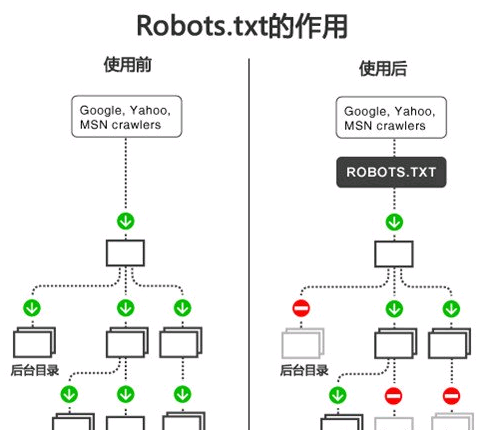
robots.txt协议书写格式
用户er-agent:这里指的是所有搜索引擎类型是一个通配符
Disallow:/admin/这儿界定是严禁爬寻admin目录下边的目录
Disallow:/require/这儿界定是严禁爬寻require目录下边的目录
Disallow:/ABC/这儿界定是严禁爬寻ABC目录下边的目录
Disallow:/cgi-bin/*.htm严禁访问/cgi-bin/目录下的全部以".htm"为后缀名的URL(包括子目录)。
Disallow:/*?*严禁访问网站中全部包括疑问(?)的网址
Disallow:/.jpg$严禁爬取网页页面全部的.jpg格式的照片
Disallow:/ab/adc.html严禁抓取ab文件夹下边的adc.html文档。
Allow:/cgi-bin/ 这儿界定是容许爬寻cgi-bin目录下边的目录
Allow:/tmp这儿界定是容许爬寻tmp的全部目录
Allow:.htm$仅容许访问以".htm"为后缀名的URL。
Allow:.gif$容许爬取网页页面和gif格式照片
Sitemap:网站地形图告知网络爬虫这一网页页面是网站地形图
文档使用方法
例1.严禁全部搜索引擎访问网站的一切一部分
User-agent:*
Disallow:/
实例分析:淘宝的Robots.txt文件
User-agent:Baiduspider
Disallow:/
User-agent:baiduspider
Disallow:/
很显而易见淘宝网不允许百度搜索的智能机器人访问其网站下其全部的目录。
例2.容许全部的robot访问(或是还可以建一个空文档“/robots.txt”file)
User-agent:*
Allow: /
例3.严禁某一搜索引擎的访问
User-agent:BadBot
Disallow:/
例4.容许某一搜索引擎的访问
User-agent:Baiduspider
allow:/
例5.一个简易事例
在这个事例中,该网站有三个目录对搜索引擎的访问干了限定,即搜索引擎不容易访问这三个目录。
必须留意的是对每一个目录务必分离申明,而不必写出“Disallow:/cgi-bin//tmp/”。
User-agent:后的*具备独特的含意,意味着“anyrobot”,因此在该文件中不可以有“Disallow:/tmp/*”or“Disallow:*.gif”那样的纪录出現。
User-agent:*
Disallow:/cgi-bin/
Disallow:/tmp/
Disallow:/~joe/
Robot独特主要参数:
容许Googlebot:
假如您要拦截除Googlebot之外的全部数据漫游器不可以访问您的网页页面,能够应用以下英语的语法:
User-agent:
Disallow:/
User-agent:Googlebot
Disallow:
Googlebot追随偏向它自身的行,而不是偏向全部数据漫游器的行。
“Allow”扩展名:
Googlebot可分辨称之为“Allow”的robots.txt规范扩展名。别的搜索引擎的数据漫游器将会无法识别此扩展名,因而请应用您很感兴趣的别的搜索引擎开展搜索。“Allow”行的功效基本原理彻底与“Disallow”行一样。只需列举您要容许的目录或网页页面就可以。
您还可以另外应用“Disallow”和“Allow”。比如,要拦截子目录中某一网页页面以外的别的全部网页页面,能够应用以下内容:
User-agent:Googlebot
Allow:/folder1/myfile.html
Disallow:/folder1/
这种内容将拦截folder1目录内除myfile.html以外的全部网页页面。
假如您要拦截Googlebot并容许Google的另一个数据漫游器(如Googlebot-Mobile),可应用”Allow”标准容许该数据漫游器的访问。比如:
User-agent:Googlebot
Disallow:/
User-agent:Googlebot-Mobile
Allow:
应用*号配对空格符编码序列:
您可应用星号(*)来配对空格符编码序列。比如,要拦截对全部以private开始的子目录的访问,可应用以下内容: User-Agent:Googlebot
Disallow:/private*/
要拦截对全部包括疑问(?)的网址的访问,可应用以下内容:
User-agent:*
Disallow:/*?*
应用$配对网址的完毕空格符
您可应用$空格符特定与网址的完毕空格符开展配对。比如,要拦截以.asp末尾的网址,可应用以下内容: User-agent:Googlebot
Disallow:/*.asp$
您可将此模式匹配与Allow命令相互配合应用。比如,假如?表达一个应用程序ID,您可清除全部包括该ID的网址,保证Googlebot不容易爬取反复的网页页面。可是,以?末尾的网址可能是您要包括的网页页面版本号。在这里状况下,可对robots.txt文件开展以下设定:
User-agent:*
Allow:/*?$
Disallow:/*?
Disallow:/*?
一行将拦截包括?的网址(实际来讲,它将拦截全部以您的网站域名开始、后接随意字符串数组,随后是疑问(?),然后也是随意字符串数组的网址)。
Allow:/*?$一行将容许包括一切以?末尾的网址(实际来讲,它将容许包括全部以您的网站域名开始、后接随意字符串数组,随后是疑问(?)问。