搜索引擎发展史:分类目录(网址导航)是史前时代、文本检索是第一代、链接分析是第二代、以用户中心是第三代,
搜索引擎的3个目标:更全、更快、更准。
搜索引擎的3个核心问题:1.用户真正的需求是什么,2.哪些信息是和用户需求是真正相关的,3.哪些信息是用户可以信赖的。
搜索引擎的架构,一张图可以说明情况:
搜索引擎的整体架构示意图:
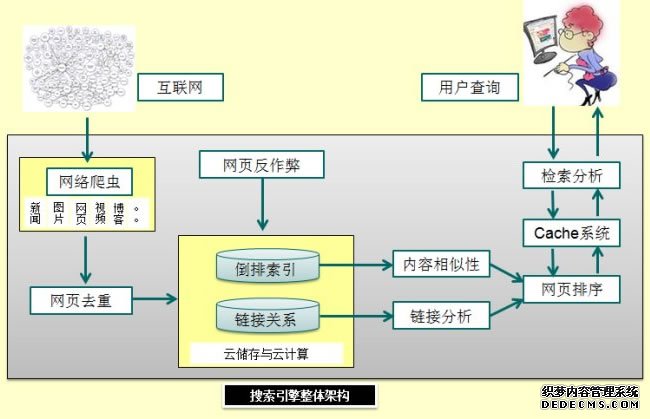
我们来看一下搜索引擎的架构(上图):
网络爬虫爬行互联网连接;
网页计算去重;
添加索引;
内容,链接计算;
网页排序;
形成对应词典,存入cache系统;
用户检索;
分析内容,调出词典内容
这基本上是一个网页从产生到呈现的过程,当然这个过程很复杂,这里只是简单的比拟出来。不过我们可以看到,网络的爬虫对我们网站是何等的重要,这也是很多卖蜘蛛池的原因吧。其次是网页的去重,因为现在百度自身服务器内部很多的网页缓存,蜘蛛爬去过得内容百度会经过一系列的计算后去除重复网页,这里面有一个比较复杂的算法,这个以后可以详细来讲。`
网页排序之后就是生成关键词的词典存入搜索引擎的Cache系统,一方面可以快速的提供用户查询信息,另一方面就是减轻搜索引擎的计算压力。
除了上述的子功能模块,“反作弊”模块也日益重要。
互联网页面划分为五个部分:1.已下载网页集合、2.已过期网页集合、3.待下载网页集合、4.可知网页集合、5.不可知网页集合。
网络爬虫分为:批量性爬虫、增量型爬虫、垂直型爬虫。
爬虫抓取的策略:1.宽度优先遍历、2.非完全PageRank、3.OPIC(Online Page Importantance Computation)、4.大站优先。
网页更新策略:1.历史参考策略、2.用户体验策略、3.聚类抽样策略